Reinforcement learning I - Temporal difference learning
Motivation
After I've started working with reward-modulated STDP in spiking neural networks, I got curious about the background of research on which it was based. This led me to the book by Richard Sutton and Andrew Barto called "Reinforcement Learning". The book is from 1998 and it's freely readable on the internet! In the book's Introduction they cover the example of an agent learning to beat a given (imperfect) agent in the game of Tic Tac Toe. Two remarks have to be made: 1. The agent has to be imperfect because a perfect agent in Tic Tac Toe (if it's the one doing the first move) can never be beaten. 2. The agent does not learn to play Tic Tac Toe, this skill is assumed, but it learns a value map for its policy.
Since I liked the example and wanted to try it out myself, I decided to write this blog post about it. By the way, the code can be found on github (run ttt_new.py).
Introduction
A few quotes taken from [Sutton & Barto 2005]:
Reinforcement learning is different from supervised learning, the kind of learning studied in most current research in machine learning, statistical pattern recognition, and artificial neural networks. Supervised learning is learning from examples provided by a knowledgable external supervisor.
Clearly, such an agent must be able to sense the state of the environment to some extent and must be able to take actions that affect the state. The agent also must have a goal or goals relating to the state of the environment. The formulation is intended to include just these three aspects--sensation, action, and goal--in their simplest possible forms without trivializing any of them.
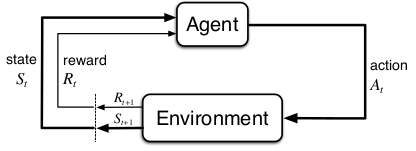
Figure taken from [Sutton & Barto 2005]
One of the challenges that arise in reinforcement learning and not in other kinds of learning is the trade-off between exploration and exploitation. To obtain a lot of reward, a reinforcement learning agent must prefer actions that it has tried in the past and found to be effective in producing reward. But to discover such actions, it has to try actions that it has not selected before. The agent has to exploit what it already knows in order to obtain reward, but it also has to explore in order to make better action selections in the future. The dilemma is that neither exploration nor exploitation can be pursued exclusively without failing at the task.
The 4 elements of reinforcement learning
Quotes taken from [Sutton & Barto 2005]
-
Roughly speaking, a policy is a mapping from perceived states of the environment to actions to be taken when in those states. [...] In some cases the policy may be a simple function or lookup table, whereas in others it may involve extensive computation such as a search process. The policy is the core of a reinforcement learning agent in the sense that it alone is sufficient to determine behavior. In general, policies may be stochastic.
-
A reward function defines the goal in a reinforcement learning problem. Roughly speaking, it maps each perceived state (or state-action pair) of the environment to a single number, a reward, indicating the intrinsic desirability of that state. A reinforcement learning agent's sole objective is to maximize the total reward it receives in the long run.
-
Whereas a reward function indicates what is good in an immediate sense, a value function specifies what is good in the long run. Roughly speaking, the value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. [...] We seek actions that bring about states of highest value, not highest reward, because these actions obtain the greatest amount of reward for us over the long run. [...] Rewards are basically given directly by the environment, but values must be estimated and reestimated from the sequences of observations an agent makes over its entire lifetime. In fact, the most important component of almost all reinforcement learning algorithms is a method for efficiently estimating values. The central role of value estimation is arguably the most important thing we have learned about reinforcement learning over the last few decades.
-
The fourth and final element of some reinforcement learning systems is a model of the environment. This is something that mimics the behavior of the environment. For example, given a state and action, the model might predict the resultant next state and next reward.
Learning a value function for Tic Tac Toe
The learning process comprises N games. Each game consists of $K \geq 3$ turns. At the beginning of every game, the board gets reset to a state in which all nine fields are empty. Our agent plays Os and therefore plays the first turn in every game. At the beginning of the learning process the value map is initialized to 0.5 for every board state except for board states that show winning configurations for O, those have value 1.0, and board states that show draws or winning configurations for X, those have value 0.0.
Our agent can make two types of moves (actions): 1. Exploratory moves that ignore the value of the resulting board configuration and 2. Greedy moves that seek to maximize the value of the resulting board configuration. The probability of picking an exploratory move is $p_{ex}$.
After every greedy move, we update the value of the state $s$ before our opponents last move to become a bit closer to the value of the state $s'$ after our last move: $V(s) \leftarrow V(s) + \alpha [V(s') - V(s)]$. This is detailed in the following picture:
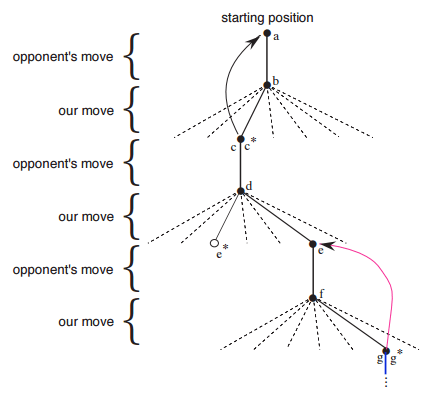
Figure taken from [Sutton & Barto 2005]
The idea behind this update rule is to make the value of that would have resulted from our previous move closer to the value after our current move. This way, the value propagates back from the goal state along our chain of actions towards the start state.
According to [Sutton & Barto 2005],
This update rule is an example of a temporal-difference learning method, so called because its changes are based on a difference, $V(s') - V(s)$, between estimates at two different times.
Each game is a series of board configurations. For greedy turns, the agent has to calculate all board configurations for all possible actions and pick the one with the highest value. Since the value map is initialized to 0.5 for all states except winning and losing ones and since there are 19,683 board states (naively counted) it makes sense to evaluate the value map lazily (although I must admit they I have not optimized my code and I have not verified this assumption).
An implementation of TD learning for TTT
I've implemented a version of this in Python. The code can be found on github (run ttt_new.py). This version chooses exploratory steps with a probability of $p_{ex}=0.01$.
The results of running the learning agent against a sub-optimal hard-coded oponent are shown in the following image. I ran 10,000 games in total and let the agent learn after each of its moves. The probability of it winning is shown in the picture for batches of 500 games. We can see that after approximately half the games it has learned how to beat the hard-coded agent about 80% of times.
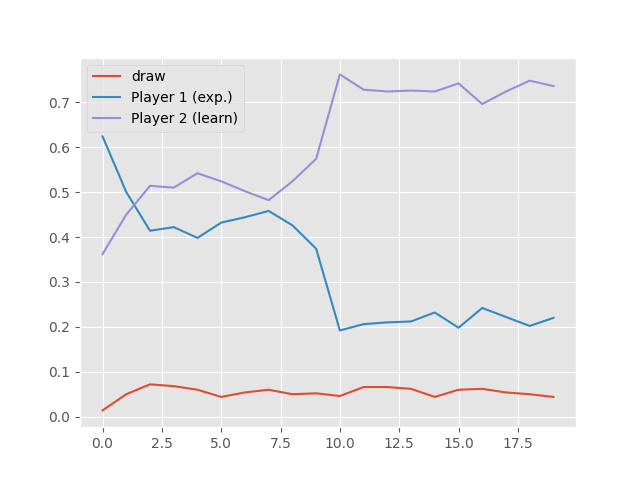
Results of a training run. Fraction of wins of each agent and draws over training runs.
Further questions
- What is dynamic programming?
- What are the combinatorics of TTT (c.f. Wikipedia article)
References
- [Sutton & Barto 2005] http://incompleteideas.net/book/first/ebook/node10.html
- My code on github: https://github.com/ahartel/reinforcement_learning